I am a capable and versatile Senior Software Developer with extensive experience and a focused approach to providing technical consultancy expertise and delivering high specification solutions in complex global finance & banking environments.
My previous consultancy work across various financial institutions alongside my strong background as a Trader / Quantitative Analyst in a high-profile asset management firm allows me to skilfully develop world-class server and client-side systems, including OMS, Risk, P&L, E-trading, electronic market-making applications for market leading financial institutions.
As an accomplished IT expert, I successfully lead major projects, deliver efficient, modern applications, and ensure that technological resources meet organisation's short and long-term needs. I effortlessly align enterprise goals with feasible technological concepts, ensure full regulatory compliance across multiple systems, manage key stakeholders effectively, and expertly communicate highly technical information to non-technical personnel at all levels of business.
Microsoft Overview of Azure features, Services and comon uses
Microsoft Azure is an open and flexible cloud platform that enables you to quickly build, deploy, and manage applications across a global network of Microsoft-managed datacenters.
You can build applications using any language, tool,or framework. And you can integrate your public cloud applications with your existing IT environment.
Microsoft Four primary models for building and running apps :
Since Bitcoin was introduced more than a decade ago, its price has been rapidly rising and frequently associated with high volatility. Historically speaking, the rapid changes in Bitcoin price and value have made it consistently volatile.
Like most existing digital currencies or cryptocurrencies, Bitcoin is a very volatile cryptocurrency. Many past instances have shown how volatile Bitcoin value and price have been and can be; for example, between November 2017 and December 2017, its price had increased by at least 220 percent.
But why has bitcoin price and value been so volatile? Well, the upward and downward price fluctuations and volatility of Bitcoin price on cryptocurrency exchanges are determined by many factors. This article discusses 11 factors that have determined and can still determine Bitcoin price volatility, and Bitcoin price and value around a particular time period. Now let’s get right into it: the 11 factors are as follows:
What a crappy thing to get. Splitting headache (no amount of paracetamol helps), shivers, unbelievable fatigue, neurological symptoms (I’m too emotional), body temp of over 38C at all times. To sum up – hell.
Take it seriously people, I’m forced to take off a week of work. This is not fun when you are a contractor
Behind the scenes the implementation uses SemaphoreSlim to do all the heavy lifting which already has a support for async/await.
You would normally use AsyncLock within a “using” statement. To keep the implementation as simple as possible I do not use any cancellation tokens for any of the operations.
Usage:
private readonly AsyncLock _lock = new AsyncLock();
public async Task DoSomethingAsync()
{
using (await _lock.EnterAsync())
{
await Task.Delay(TimeSpan.FromSeconds(1));
}
}
Simples
This blog article shows the resources for C# 9.0. Whether it is available in .NET Framework, officially I understand it is, no. People do claim it works. It is time for you to find out.
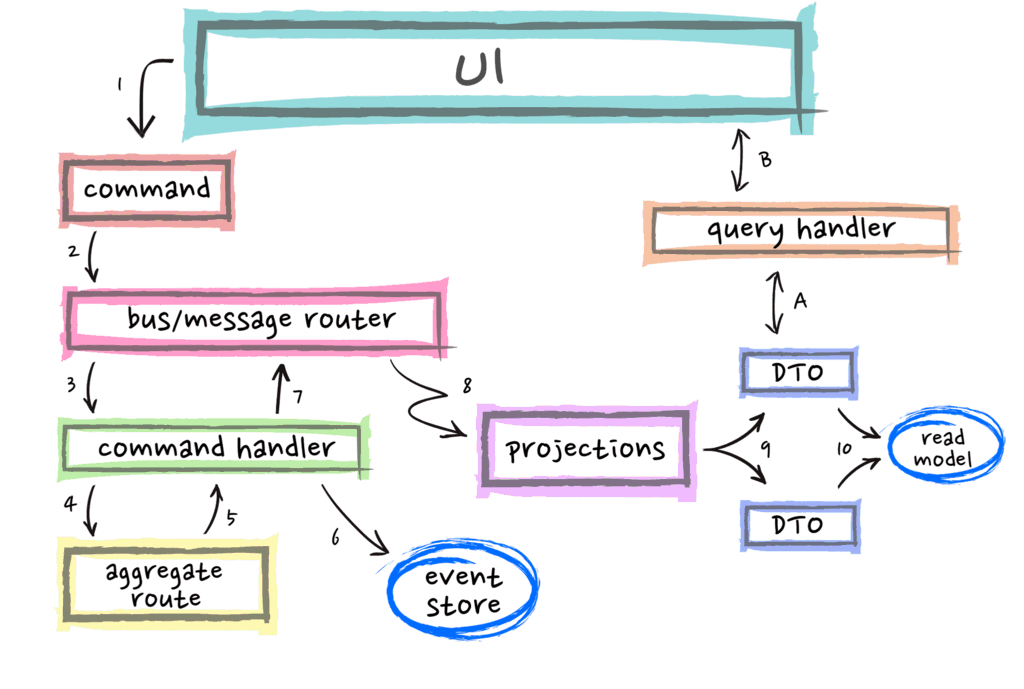
CQRS stands for Command Query Responsibility Segregation. As the name suggests, we split the application in two parts: Command-Side and Query-Side. Now one will ask what this command and query means? Okay, so –
Commands are the ones that change the state of the object or entity, also called modifiers or mutators.
Queries are those that returns the state of the entity, and do not change anything. The another term for that will be accessors.
Why is it required?
In traditional data management systems, both commands and queries are executed against the same set of entities, having a single reprsentation or view. The CRUD operations are applied to a single datastore, the same entity or object is accessed to handle both read and write operations.
Issues with having single view for both read and write side –
Introduces the risks of data contention.
Managing permissions and security become complex as same objects are exposed to both read and write operations.
How CQRS solves this problem?
The CQRS pattern holds the idea that the method should either change the state of the entity, or returns the result, but not both. Segregating models for read and write side reduces the complexity that comes with having single view for both of them.
Benefits of CQRS –
Separate command and query models, results in simplified design and implementation of the system and overall reduction of complexity.
One can easily optimise the read side of the system separately from the write side, allows scaling each differently as per the load on the side. For example – Read datastores often encounters greater load, and hence can be scaled without affecting the write datastores.
You can provide multiple views of your data for querying purpose depending on the use cases.
How CQRS works?
CQRS is mainly used in conjuction with Event Sourcing. The write side model of the CQRS-based system handles the events persistence, acting as a source of information for the read side. The read model of the system provides materialized views of the data, typically as highly denormalized views.
We know that .NET 5.0 makes it possible to develop WPF and Windows Forms applications. However, at the time of writing, Visual Studio templates haven’t been updated to new target framework: desktop applications are still created using .NET Core 3.1. So, for example, the project file for a WPF application is the following:
However, we can easily update it to use .NET 5.0. We just need to change Sdk attribute (line 1) and the TargetFramework tag (line 5):
In particular, we don’t have anymore an Sdk that relates to desktop applications. Instead, we have a target framework moniker (TFM) that is OS-specific, net5.0-windows. This is because the standard net5.0 moniker only includes technologies that work cross-platform. Specifying an OS-specific TFM makes APIs that are specific to an operating system available to ours applications (in our case, desktop applications on Windows). Of course, OS-specific TFMs also inherit every API available…
After using Rider for a day I just can’t go back to using Visual Studio 2019 + ReSharper combo. No matter how much you tweak it, it is still going to be very slow, especially for larger solutions.
I’m not someone who’s using a 5 year old notebook, my whole PC is build around being able to develop faster (almost), hence all my primary SSDs are the fastest M.2 drives around: C:\ 1TB, D:\ 2TB – SEAGATE FIRECUDA 520 GEN 4 PCIe NVMe (up to 5000MB/R, 4400MB/W) – I never saw anything faster than that on the market yet.
My PC Specs
In addition I have 128GB of RAM (DDR4 3200MHz) and AMD Ryzen Threadripper 3970X 32 Core CPU (3.7GHz – 4.5GHz, 147MB CACHE) which isn’t the fastest CPU around and I could have gone for the 64 core variant but that would be way over the top, since my overall CPU usage never goes up above 3%! while using VS 2019
CPU usage jump to 25% when starting Visual Studio and peaked at 87% while doing a rebuild on a large project PS: this is the first time I saw my CPU utilisation so high Can’t resist any opportunity to show off my PC 🙂
The reason I deviated from conformity is because I had to modify .NET Framework version in several projects. Doing it in VS 2019 is extremely painful, in Rider you click and edit. It’s not slow, you don’t have to wait at all.
Where Rider is at its best
Here are some of the Rider features which I liked the most:
Rider = IntelliJ IDEA + ReSharper Rider comes with all the goodies of ReShaper without the performance tax. For the developers who cannot live without ReSharper, this can be huge.
Rider = IntelliJ IDEA + ReSharper
Faster build time: Rider can improve the build time drastically as compared to Visual Studio by applying heuristics to only build the projects that need to be updated. It can be a real performance booster for large solutions. This post explains the incremental build feature in details.
Note: This feature was already available with ReSharper Build. So, if you are using ReSharper build instead of Visual Studio build management, then you might be already familiar with this.
Seamless external source debugging: One of the features I liked about Rider was debugging external libraries/ nuget packages seamlessly like they are part of your code. And when you do not need to debug external source, you can turn off the feature.
Enable external source debug option
First-class support for Typescript/ Javascript debugging: I always felt Typescript/Javascript received a stepchild treatment in Visual Studio. With Rider, Typescript has first-class debugging support. You can debug within the IDE without switching to browser dev-tools.
Better Unit test experience: I have been a fan of ReSharper Unit test explorer window. And Rider only takes this forward. You can create multiple test window sessions and run only a subset of tests.
Great Git plugin: It would be an understatement to say that Rider’s Git plugin is better than Visual Studio. It offers the code analysis even during the merge, which can be huge since you can fix compile-time error or remove unused references at the time of merge.
Handling of large solutions: It is reasonable to expect that loading a large solution will take time. With Visual Studio, I encountered UI getting hanged several times during the project startup. Rider, on the other hand, handles it more gracefully. Like ReSharper, there is also an option to disable solution wide code analysis which can improve the load time.
Project Properties: The project properties dialog in Rider supports the latest features of the new SDK project such as multi-target, setting language version, Nuget properties etc.
Project properties options in Rider
Event Log, Terminal window, create gist etc.: Rider comes up with an Event log window which the logs every event that happens with in the IDE. It also has a built-in Terminal and some excellent little features such create GitHub Gists from within the IDE. One other thing that impressed me was the ability to create custom “Run/Debug” templates. It offers much more than running a single project or “Multiple startup projects” option in Visual Studio.
There are some issues around NuGet handling but at the same time there are so many issues in VS 2019.
Its been a while since I’ve posted here and also written an article. But I took some time last night to create an article about gRPC. Here is an abstract about the article
So if you have been around a while you will have undoubtedly come across the need to perform some sort of remote procedure call. There are many frameworks that allow this, WebApi, WCF, just about any REST Api you can think of, Service Stack etc etc
This is all fairly standard stuff we call a remote systems method with some parameters (or not) and get a response (or not)
Those of you that have also used things like WCF will recall that WCF also supported Duplex channels, where the server side code was capable of calling clients back on a callback channel. This is quite useful for things like notifications/price updates things like that.
 Microsoft Overview of Azure features, Services and comon uses
Microsoft Overview of Azure features, Services and comon uses